As I mentioned in an earlier post, last June I had the great pleasure and honor of participating in a discussion meeting on Language in Developmental and Acquired Disorders hosted by the Royal Society and organized by Dorothy Bishop, Kate Nation, and Karalyn Patterson. Among the many wonderful things about this meeting was that it brought together people who study similar kinds of language deficit issues but in very different populations -- children with developmental language deficits such as dyslexia and older adults with acquired language deficits such as aphasia. Today, the special issue of Philosophical Transactions of the Royal Society B: Biological Sciences containing articles written by the meeting's speakers was published online (Table of Contents).
Monday, December 9, 2013
Monday, November 25, 2013
Does Malcolm Gladwell write science or science fiction?
Malcolm Gladwell is great at writing anecdotes, but he dangerously masquerades these as science. Case studies can be incredibly informative -- they form the historical foundation of cognitive neuroscience and continue to be an important part of cutting-edge research. But there is an important distinction between science, which relies on structured data collection and analysis, and anecdotes, which rely on an entertaining narrative structure. His claim that dyslexia might be a "desireable difficulty" is maybe the most egregious example of this. Mark Seidenberg, who is a leading scientist studying dyslexia and an active advocate, has written an excellent commentary about Gladwell's misrepresentation of dyslexia. The short version is that dyslexia is a serious problem that, for the vast vast majority of people, leads to various negative outcomes. The existence of a few super-successful self-identified dyslexics may be encouraging, maybe even inspirational, but it absolutely cannot be taken to mean that dyslexia might be good for you.
In various responses to his critics, Gladwell has basically said that people who know enough about the topic to recognize that (some of) his conclusions are wrong, shouldn't be reading his books ("If my books appear to a reader to be oversimplified, then you shouldn't read them: you're not the audience!"). This is extremely dangerous: readers who don't know about dyslexia, about its prevalence or about its outcomes, would be led to the false conclusion that dyslexia is good for you. The problem is not that his books are oversimplified; the problem is that his conclusions are (sometimes) wrong because they are based on a few convenient anecdotes that do not represent the general pattern.
Another line of defense is that Gladwell's books are only meant to raise interesting ideas and stimulate new ways of thinking in a wide audience, not to be a scholarly summary of the research. Writing about science in a broadly accessible way is a perfectly good goal -- my own interest in cognitive neuroscience was partly inspired by the popular science writing of people like Oliver Sacks and V.S. Ramachandran. The problem is when the author rejects scientific accuracy in favor of just talking about "interesting ideas". Neal Stephenson once said that what makes a book "science fiction" is that it is fundamentally about ideas. It is great to propose new ideas and explore what they might mean. But if we follow that logic, then Malcolm Gladwell is not a science writer, he is a science fiction writer.
Monday, October 21, 2013
The mind is not a (digital) computer
The "mind as computer" has been a dominant and powerful metaphor in cognitive science at least since the middle of the 20th century. Throughout this time, many of us have chafed against this metaphor because it has a tendency to be taken too literally. Framing mental and neural processes in terms of computation or information processing can be extremely useful, but this approach can turn into the extremely misleading notion that our minds work kind of like our desktop or laptop computers. There are two particular notions that have continued to hold sway despite mountains of evidence against them and I think their perseverance might be, at least in part, due to the computer analogy.
The first is modularity or autonomy: the idea that the mind/brain is made up of (semi-)independent components. Decades of research on interactive processing (including my own) and emergence have shown that this is not the case (e.g., McClelland, Mirman, & Holt, 2006; McClelland, 2010; Dixon, Holden, Mirman, & Stephen, 2012), but components remain a key part of the default description of cognitive systems, perhaps with some caveat that these components interact.
The second is the idea that the mind engages in symbolic or rule-based computation, much like the if-then procedures that form the core of computer programs. This idea is widely associated with the popular science writing of Steven Pinker and is a central feature of classic models of cognition, such as ACT-R. In a new paper just published in the journal Cognition, Gary Lupyan reports 13 experiments showing just how bad human minds are at executing simple rule-based algorithms (full disclosure: Gary and I are friends and have collaborated on a few projects). In particular, he tested parity judgments (is a number odd or even?), triangle judgments (is a figure a triangle?), and grandmother judgments (is a person a grandmother?). Each of these is a simple, rule-based judgment, and the participants knew the rule (last digit is even; polygon with three sides; has at least one grandchild), but they were nevertheless biased by typicality: numbers with more even digits were judged to be more even, equilateral triangles were judged to be more triangular, and older women with more grandchildren were judged to be more grandmotherly. A variety of control conditions and experiments ruled out various alternative explanations of these results. The bottom line is that, as he puts it, "human algorithms, unlike conventional computer algorithms, only approximate rule-based classification and never fully abstract from the specifics of the input."
It's probably too much to hope that this paper will end the misuse of the computer metaphor, but I think it will be a nice reminder of the limitations of this metaphor.
The first is modularity or autonomy: the idea that the mind/brain is made up of (semi-)independent components. Decades of research on interactive processing (including my own) and emergence have shown that this is not the case (e.g., McClelland, Mirman, & Holt, 2006; McClelland, 2010; Dixon, Holden, Mirman, & Stephen, 2012), but components remain a key part of the default description of cognitive systems, perhaps with some caveat that these components interact.
The second is the idea that the mind engages in symbolic or rule-based computation, much like the if-then procedures that form the core of computer programs. This idea is widely associated with the popular science writing of Steven Pinker and is a central feature of classic models of cognition, such as ACT-R. In a new paper just published in the journal Cognition, Gary Lupyan reports 13 experiments showing just how bad human minds are at executing simple rule-based algorithms (full disclosure: Gary and I are friends and have collaborated on a few projects). In particular, he tested parity judgments (is a number odd or even?), triangle judgments (is a figure a triangle?), and grandmother judgments (is a person a grandmother?). Each of these is a simple, rule-based judgment, and the participants knew the rule (last digit is even; polygon with three sides; has at least one grandchild), but they were nevertheless biased by typicality: numbers with more even digits were judged to be more even, equilateral triangles were judged to be more triangular, and older women with more grandchildren were judged to be more grandmotherly. A variety of control conditions and experiments ruled out various alternative explanations of these results. The bottom line is that, as he puts it, "human algorithms, unlike conventional computer algorithms, only approximate rule-based classification and never fully abstract from the specifics of the input."
It's probably too much to hope that this paper will end the misuse of the computer metaphor, but I think it will be a nice reminder of the limitations of this metaphor.
Lupyan, G. (2013). The difficulties of executing simple algorithms: Why brains make mistakes computers don’t. Cognition, 129(3), 615-636. DOI: 10.1016/j.cognition.2013.08.015
McClelland, J.L. (2010). Emergence in Cognitive Science. Topics in Cognitive Science, 2 (4), 751-770 DOI: 10.1111/j.1756-8765.2010.01116.x
McClelland JL, Mirman D, & Holt LL (2006). Are there interactive processes in speech perception? Trends in Cognitive Sciences, 10 (8), 363-369 PMID: 16843037
Tuesday, October 15, 2013
Graduate student positions available at Drexel University
The Applied Cognitive and Brain Sciences (ACBS) program at Drexel University invites applications for Ph.D. students to begin in the Fall of 2014. Faculty research interests in the ACBS program span the full range from basic to applied science in Cognitive Psychology, Cognitive Neuroscience, and Cognitive Engineering, with particular faculty expertise in computational modeling and electrophysiology. Accepted students will work closely with their mentor in a research-focused setting, housed in a newly-renovated, state-of-the-art facility featuring spacious graduate student offices and collaborative workspaces. Graduate students will also have the opportunity to collaborate with faculty in Clinical Psychology, the School of Biomedical Engineering and Health Sciences, the College of Computing and Informatics, the College of Engineering, the School of Medicine, and the University's new Expressive and Creative Interaction Technologies (ExCITe) Center.
Specific faculty members seeking graduate students, and possible research topics after the jump.
Specific faculty members seeking graduate students, and possible research topics after the jump.
Monday, September 30, 2013
New version of lme4
If you haven't realized it yet, a new version of lme4 (version 1.0-4) was released recently (Sept. 21). For an end-user like me, there were not many changes, but there were a few:
- No more using the @ operator. After a very helpful email exchange with Ben Bolker, I came to realize that I shouldn't have been using it in the first place, but I hadn't figured out all the "accessor" methods that are available (you can get a list using methods(class = "merMod")). I had been using it in two main contexts:
- To get the fixed effect coefficients with their standard errors, etc. from the summary. A better way to do that is to use coef(summary(m))
- To get model-predicted values. A better way to do that is to use fitted(m), with the added convenience that this returns proportions for logistic models, making the model fits easier (and, I think, more intuitive) to visualize. By the way, a predict() method has now been implemented, which provides an easy way to get model predictions for new data.
- There have been some changes to the optimization algorithms and some of my models that used to run fine are now giving me some convergence warnings. This seems to happen particularly for linear models with within-subject manipulations. Using the bobyqa optimizer instead of the default Nelder-Mead optimizer seems to fix the problem. This can be done by adding control=lmerControl(optimizer = "bobyqa") to the call to lmer. A minor related point: the release notes (https://github.com/lme4/lme4/blob/master/misc/notes/release_notes.md) state that the internal computational machinery has changed, so the results will not be numerically identical, though they should be very close for reasonably well-defined fits. I have found this to be true for a reasonably large set of models that I've re-run.
- When fitting logistic models, if you use lmer(..., family="binomial"), it will call glmer() as before, but now also warns you that you should probably be using glmer() directly.
Monday, June 17, 2013
Models are experiments
I spent last week at a two-part meeting on language in developmental and acquired disorders, hosted by the Royal Society. The organizers (Dorothy Bishop, Kate Nation, and Karalyn Patterson) devised a meeting structure that stimulated – and made room for – a lot of discussion and one of the major discussion topics throughout the meeting was computational modeling. A major highlight for me was David Plaut’s aphorism “Models are experiments”. The idea is that models are sometimes taken to be the theory, but they are better thought of as experiments designed to test the theory. In other words, just as a theory predicts some behavioral phenomena, it also predicts that a model implementation of that theory should exhibit those phenomena. This point of view has several important, and I think useful, consequences.
Wednesday, May 22, 2013
Choosing a journal
For almost every manuscript I've been involved with, my co-authors and I have had to have a discussion about where (to which journal) we should submit it. Typically, this is a somewhat fuzzy discussion about the the fit between the topic of our manuscript and various journals, the impact factor of those journals (even though I'm not fond of impact factors), their editorial boards (I find that the review process is much more constructive and effective when the editor is knowledgeable about the topic and sends the manuscript to knowledgeable reviewers), manuscript guidelines such as word limits, and turn-around times (which can vary from a few weeks to several months).
I've just learned about a very cool online tool, called JANE (Journal/Author Name Estimator), that provides recommendations. The recommendations are based on similarity between your title or abstract and articles published in various journals (their algorithm is described in a paper). This similarity score comprises the confidence of the recommendation and the journal recommendations come with an Article Influence score, which is a measure of how often articles in the journal get cited (from eigenfactor.org). I tried it out using the titles and abstracts of some recent (but not yet published) manuscripts and I thought it provided very appropriate recommendations. Not surprisingly, the recommendations were a little better when I provided the abstract instead of the title, but I was impressed with how well it did just based on the title (maybe this means that I write informative titles?). JANE can also be used to find authors who have published on your topic, which could be useful for suggesting reviewers and generally knowing who is working in your area, but I found this search type to be noisier, probably simply due to sample size -- a typical author has many fewer publications than a typical journal. JANE won't answer all your journal and manuscript questions, but I am looking forward to using JANE next time I find myself debating where to submit a manuscript.
I've just learned about a very cool online tool, called JANE (Journal/Author Name Estimator), that provides recommendations. The recommendations are based on similarity between your title or abstract and articles published in various journals (their algorithm is described in a paper). This similarity score comprises the confidence of the recommendation and the journal recommendations come with an Article Influence score, which is a measure of how often articles in the journal get cited (from eigenfactor.org). I tried it out using the titles and abstracts of some recent (but not yet published) manuscripts and I thought it provided very appropriate recommendations. Not surprisingly, the recommendations were a little better when I provided the abstract instead of the title, but I was impressed with how well it did just based on the title (maybe this means that I write informative titles?). JANE can also be used to find authors who have published on your topic, which could be useful for suggesting reviewers and generally knowing who is working in your area, but I found this search type to be noisier, probably simply due to sample size -- a typical author has many fewer publications than a typical journal. JANE won't answer all your journal and manuscript questions, but I am looking forward to using JANE next time I find myself debating where to submit a manuscript.
Thursday, May 16, 2013
A function for comparing groups on a set of variables
I'm often in the position of needing to compare groups of either items or participants on some set of variables. For example, I might want to compare recognition of words that differ on some measure of lexical neighborhood density but are matched on word length, frequency, etc. Similarly, I might want to compare individuals with aphasia that have anterior vs. posterior lesions but are matched on lesion size, aphasia severity, age, etc. I'll also need to report these comparisons in a neat table if/when I write up the results of the study. This means computing and collating a bunch of means, standard deviations, and t-tests. This is not particularly difficult, but it is somewhat laborious (and boring), so I decided to write a function that would do it for me. Details after the jump.
Friday, April 5, 2013
Multiple pairwise comparisons for categorical predictors
Dale Barr (@datacmdr) recently had a nice blog post about coding categorical predictors, which reminded me to share my thoughts about multiple pairwise comparisons for categorical predictors in growth curve analysis. As Dale pointed out in his post, the R default is to treat the reference level of a factor as a baseline and to estimate parameters for each of the remaining levels. This will give pairwise comparisons for each of the other levels with the baseline, but not among those other levels. Here's a simple example using the
ChickWeight data set (part of the datasets package). As a reminder, this data set is from an experiment on the effect of diet on early growth of chicks. There were 50 chicks, each fed one of 4 diets, and their weights were measured up to 12 times over the first 3 weeks after they were born.Thursday, April 4, 2013
R 3.0 released; ggplot2 stat_summary bug fixed!
The new version of R was released yesterday. As I understand it, the numbering change to 3.0 represents the recognition that R had evolved enough to justify a new number rather than the addition of many new features. There are some important new features, but I am not sure they will affect me very much.
For me, the much bigger change occurred in the update of the ggplot2 package to version 0.9.3.1, which actually happened about a month ago, but I somehow missed it. This update is a big deal for me because it fixes a very unfortunate bug from version 0.9.3 that broke one of my favorite features: stat_summary(). As I mentioned in my previous post, one of the great features of ggplot is that allows you to compute summary statistics "on the fly". The bug had broken this feature for certain kinds of summary statistics computed using stat_summary(). A workaround was developed relatively quickly, which I think is a nice example of open-source software development working well, but it's great to have it fixed in the packaged version.
For me, the much bigger change occurred in the update of the ggplot2 package to version 0.9.3.1, which actually happened about a month ago, but I somehow missed it. This update is a big deal for me because it fixes a very unfortunate bug from version 0.9.3 that broke one of my favorite features: stat_summary(). As I mentioned in my previous post, one of the great features of ggplot is that allows you to compute summary statistics "on the fly". The bug had broken this feature for certain kinds of summary statistics computed using stat_summary(). A workaround was developed relatively quickly, which I think is a nice example of open-source software development working well, but it's great to have it fixed in the packaged version.
Saturday, March 2, 2013
Why I use ggplot
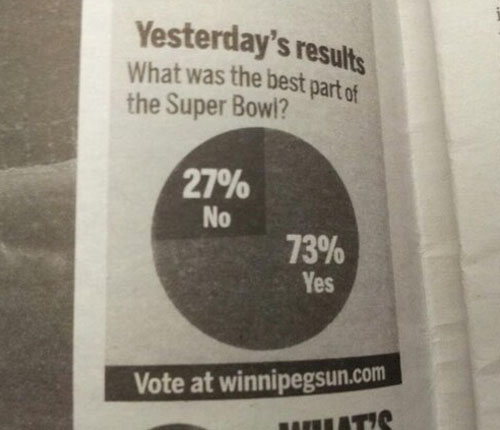
(via Flowing Data)
For the last few years I have been using the ggplot2 package to make all of my figures. I had used Matlab previously and ggplot takes some getting used to, so this was not an easy switch for me. Joe Fruehwald's Penn R work group was a huge help (and more recently, he posted this excellent tutorial). Now that I've got the hang of it, there are two features of ggplot that I absolutely can't live without.
Friday, February 8, 2013
Using R to get h5-index for a list of journals
In my last blog post I wrote about impact factors and h-index for different journals. That got me wondering about what the h5 index is for all of the journals that I read and may want to publish in. I could look them all up individually, but that sounds boring and monotonous. I'd much rather figure out how to get R to do it for me. I've never done this kind of thing with R before, so it took a little while, but I wrote a simple function that takes a journal name and returns its h5-index.
Thursday, February 7, 2013
Impact factor vs. H-index
I've been thinking about journal rankings and impact factors lately, partly because I noticed that impact factors and H-index sometimes give quite different rankings for journals. To pick one example, Neuropsychologia and Cortex are two very good cognitive neuroscience journals that publish similar sorts of articles, but the impact factor for Cortex is substantially higher than for Neuropsychologia (6.08 vs. 3.636), whereas the H-index is substantially higher for Neuropsychologia than for Cortex (67 vs. 41). In case you are unfamiliar with these measures, impact factor is basically the mean number of citations to articles that were published in the past 2 years; H-index is the largest number h such that h articles have at least h citations each. So the articles published in Cortex have been cited an average of about 6 times and there are 41 articles that have been cited at least 41 times; the articles in Neuropsychologia have been cited an average of about 3.6 times and there are 67 articles that have been cited at least 67 times. Since both measures are based on citation rates, why do they give different rankings?
Friday, January 18, 2013
Using R to create visual illusions
This brings together two of my favorite (professional) things: R and visual illusions. Aside from being an extremely impressive application of R, it's a cool way of making it clear that the illusion is, in fact, an illusion. Here's a simple example:
library(grid)
grid.newpage()
grid.rect(c(1,3,1,3)/4, c(3,3,1,1)/4, 1/2, 1/2,
gp = gpar(col = NA, fill = gray(1:4/5)))
grid.rect(c(1,3,1,3)/4, c(3,3,1,1)/4, 1/6, 1/6,
gp = gpar(col = NA, fill = gray(0.5)))

library(grid)
grid.newpage()
grid.rect(c(1,3,1,3)/4, c(3,3,1,1)/4, 1/2, 1/2,
gp = gpar(col = NA, fill = gray(1:4/5)))
grid.rect(c(1,3,1,3)/4, c(3,3,1,1)/4, 1/6, 1/6,
gp = gpar(col = NA, fill = gray(0.5)))
Which creates the image below. The first call to grid.rect makes a set of four squares of different shades of gray, the second call inserts smaller squares inside those larger squares. The smaller squares are all the same shade of gray - which is obvious from the R code - but they appear to be different: the one in the upper left appears lightest and the one in the lower right appears darkest.
Subscribe to:
Posts (Atom)